학과 스터디에서 주 1회 논문 리뷰를 돌아가며 하기로 했다.
첫 논문은 현재 생성형AI 발전의 근본이라고 볼 수 있는 transformer 소개 논문 "Attention is all you need".
이름부터 "어탠션이면 충분해"인 만큼 여타 아키텍처는 버리고 어탠션만 채택해 학습시간을 줄이고 정확도를 끌어올린 혁신적인 알고리즘이라고 할 수 있다.
사실 어탠션 매커니즘이 이때 등장한 게 아니라, self attention을 적극 활용했다는 점이 주의사항이기는 하지만,
DNN --> RNN --> CNN 순으로 공부해 온 사람이라면 이쯤 해서 최신 모델에 적극 사용되는 transformer와 self multi-head attention에 대해서 숙지할 필요가 있다고 본다.
Abstract:
The dominant sequence transduction[심1] models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder. The best
performing models also connect the encoder and decoder through an attention[심2]
mechanism. We propose a new simple network architecture, the Transformer,
based solely on attention mechanisms, dispensing with recurrence and convolutions
entirely. Experiments on two machine translation tasks show these models to
be superior in quality while being more parallelizable and requiring significantly
less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-
to-German translation task, improving over the existing best results, including
ensembles, by over 2 BLEU[심3] . On the WMT 2014 English-to-French translation task,
our model establishes a new single-model state-of-the-art BLEU score of 41.8 after
training for 3.5 days on eight GPUs, a small fraction of the training costs of the
best models from the literature. We show that the Transformer generalizes well to
other tasks by applying it successfully to English constituency parsing both with
large and limited training data.
[심1]특정 데이터셋에 한해서 학습하는 방식. 기존의 모델들은 RNN 또는 CNN 베이스의 인코더-디코더 형태였음.
[심2]기존에도 어텐션 매커니즘은 사용했으나, 본 연구는 어텐션만을 활용해서 기계번역 결과의 질적 향상을 이루었을 뿐 아니라, 연산을 병렬구조화 시켜 GPU연산의 효율성을 가능케함으로써 학습시간 단축을 이룩함.
[심3]Bi-Lingual Evaluation Understudy. 기계번역모델의 성능평가지표. 높을수록 좋은 모델. 이외에 Perplexity(PPL)도 있으나, 이는 기계번역 성능을 직접적으로 반영하는 수치라고 보기에 어려움.
1. Introduction
기존 모델의 한계 지적
1) h(t)라는 현시점을 예측할 때 h(t-1)이라는 직전 시점의 hidden state를 반영하여 추론하기 때문에, long-term dependency 문제 해결 불가.
2) 병렬처리 불가능. --> RNN 구조와 attention 매커니즘 함께 활용.
Transformer 제안
1) RNN 구조 제거, rely entirely on Attention --> 인풋과 아웃풋 간의 global dependency 확보.
2) 고성능 + 학습비용저렴.
2. Background
Transformer: 기존의 효과적인 Conv. 알고리즘의 시간복잡도였던 O(n), O(logN)을 O(1)로 줄임.
Self-attention 소개
1) 자기자신(단어)이 속한 문장을 맥락으로 사용해서 다시 표현.
2) 독해, 요약, 함축 등 다양한 과제에서 활용됨.
3. Model Architecture
인코더-디코더 구조
Input seq of symbol representations(X) --> encoder --> continuous representations(X)
Given Z --> decoder --> output seq of symbols(Y)
모든 스텝이 자기회귀적 구조; 다음 단어를 생성하기 위한 추가적인 input으로 이전 output을 사용

3.1 Encoder and Decoder Stacks
1) Encoder(identical 6 layers): 각 층마다 두개의 sub-layers 존재.
(i) multi-head self-attention
(ii) position-wise fully connected feed-forward network
각 층의 아웃풋: LayerNorm(x+ Sublayer(x)) ; 512 dimention 유지
2) Decoder(identical 6 layers): 각 층마다 세개의 sub-layers 존재
(i) multi-head self-attention
(ii) position-wise fully connected feed-forward network
(iii) multi-head attention over the output of the encoder stack
3.2 Attention
1) Scaled Dot-Product Attention
Attention값을 계산하는 함수에는 dot product attention 또는 additive attention(with single-layer FFN)을 사용할 수 있으나, 본 연구에서는 시공간적 효율성을 고려하여 dot product를 사용함.
다만, dot product를 차용하는 경우 dimension의 증가에 따라 output 값이 기하급수적으로 증가하기 때문에 이를 상쇄하는 역할로 sqrt(dimension)로 나누어준다.
2) Multi-head attention

Idea: linearly project V, K, Q 8 times (projections are parameter matrices W with each dimensions) --> parallelly perform attention --> concat --> projection
3) Applications of Attention in our Model
Transformer는 multi-head attention을 3가지 방식으로 활용함.
(i) Encoder-decoder layer: Q는 이전 decoder에서 오고, K, V는 encoder의 output에서 옴 --> 디코더의 모든 포지션이 인풋시 퀀스의 모든 포지션에 연결됨.
(ii) 인코더 내의 self-attention layer: Q, K, V 모두 이전 encoder의 output에서 옴 --> 인코더의 모든 포지션이 인풋시퀀스의 모든 포지션에 연결됨.
(iii) 디코더 내의 self-attention layer: 인코더와 유사.
3.3 Position-wise Feed-Forward Networks
각 레이어에 FFN가 붙어 있는데, 활성화함수로 ReLu를 사용한다는 점에서 동일하나, 각각 다른 connection weight을 사용하게 됨.
입출력 512차원, 내부 2048차원
3.4 Embeddings and Softmax
Input tokens와 output tokens의 차원을 변환하기 위해 embedding layer를 사용하고, weight matrix는 동일하게 설정하고 √dmodel를 곱함.
3.5 Positional Encoding
Transformer는 RNN / CNN 구조를 채택하지 않고 있기 때문에, 문장 내에서 단어가 어느 위치에 등장하는지에 대해서는 학습할 방법이 없음 --> encoder와 decoder의 bottom에 positional encoding을 추가 --> sine/cosine함수로 인코딩값 정의
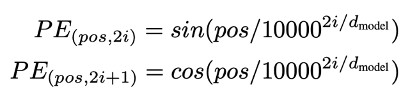
왜 이 함수를 사용? --> 모델이 상대적으로 쉽게 학습 가능.
Learned-positional encoding 방식과 fixed-positional encoding 방식이 있으나 성능은 비슷했고, fixed 방식이 학습한 과정에서의 시퀀스 길이보다 더 긴
시퀀스를 추론할 수 있기 때문에 본 연구에서는 fixed를 차용함.
4. Why self-attention?
Self-attention을 사용하는 세가지 이유
1) 각 레이어의 연산 복잡도
2) 병렬화될 수 있는 연산량
3) NN 내 long-range dependency의 path length가 짧음.
기존 방식의 한계:
RNN (Recurrent Neural Network)이나 LSTM은 입력 시퀀스를 순차적으로 처리.
Ex) 첫 번째 단어 → 두 번째 단어 → … → n번째 단어
이런 방식은 멀리 떨어진 단어들 사이의 의존 관계를 파악하는 데 오랜 시간과 많은 연산이 필요함. 시간 복잡도는 𝑂(𝑛)이고, 병렬화가 어려움. 멀리 있는 단어 간의 정보가 전파되기 어렵고, gradient vanishing 문제가 발생할 수 있습니다.
Self-Attention의 장점:
1) 모든 단어 쌍을 한 번에 비교할 수 있음.
각 단어의 representation을 다른 모든 단어와 바로 연결해서 상호작용 가능 --> 멀리 떨어진 단어 간 관계도 빠르고 효과적으로 학습 가능.
시간 복잡도는 병렬 연산 시 𝑂(1)로 처리됨 (다만 연산량은 여전히 𝑂(𝑛2)임).
2) 입력 문장을 한 번에 모두 처리할 수 있습니다 → 완전 병렬화 가능.
각 단어에 대해 Query, Key, Value를 계산하고, dot-product attention으로 모든 단어 쌍 간 유사도를 계산한 후 weighted sum을 적용.
3) 모든 단어가 모든 단어와 직접 연결되므로 path length = 1이다. 즉, 어떤 두 단어 사이도 직접 연관지을 수 있기 때문에 문맥 파악이 훨씬 빠르고 명확 + 정보의 흐름이 왜곡되거나 손실되지 않음

5. Training
1) Training data and batching
(i) En – De: 4.5million sentence pairs; vocabs 37000 tokens
(ii) En – Fr: 36M sentences and 32000 words.
문장길이가 유사한 것들을 배치로 묶었음.
각 배치는 source 25000, target 25000개 정도로 구성.
2) Hardware and schedule -- 아래 표
3) Optimizer -- 아래 표

* Big model은 3.5days 소요됨.
4) Regularizations
(i) Residual Dropout: Add&Norm 직전에 10% dropout 적용.
(ii) Label Smoothing: PPL은 안 좋아지나, 정확도와 BLEU가 올라감.
(iii) L2는 사용하지 않음 (GPT피셜)
6. Results

Outperform in BLEU, and also at Training cost.
- Base model: averaged 5 last checkpoints.
- Big model: averaged 20 last checkpoints.
최적의 하이퍼파라미터를 찾기 위한 variation 실험.
1) attention heads 너무 많으면 BLEU 감소
2) attention key size 줄이면 BLEU 감소
3) bigger models are better
4) dropout is very helpful
5) fixed positional encoding(sinusoidal) VS learned positional encoding : identical
English Constituency Parsing: Transformer가 다른 task도 할 수 있는지 실험.

2) 기존의 sequence-to-sequence 모델을 활용하여 구문 트리를 토큰 시퀀스로 변환
3) 문제를 기계 번역처럼 다뤄, 문장을 트리 시퀀스로 변환하는 Seq2Seq 문제로 모델을 학습
4) Self-attention 만으로도 구문 구조를 파악 가능함이 검증되었고(RNN보다 뛰어난 성능 : F1-score), transformer의 범용성에 대한 power를 검증함.
[심4]유명한 영어 구문 분석 데이터셋. Wall Street Journal 섹션에서 추출된 문장들로 구성

7. Conclusion
의의: attention mechanism만 사용한 최초의 seq transduction 모델
성과: 기계번역 분야에서 기존의 RNN, CNN 기반 모델들 능가.
'99_DS' 카테고리의 다른 글
| 전이학습과 파인튜닝 (4) | 2025.05.24 |
|---|---|
| [paper review] Isolation Forest (2009) (0) | 2025.05.22 |
| [딥러닝] 경사하강법의 응용 (0) | 2025.05.08 |
| [딥러닝] 역전파 (1) | 2025.05.08 |
| AI 기술의 진화: 프롬프트 엔지니어링부터 파운데이션 모델 트레이닝까지 (0) | 2025.05.06 |


